
いつか調べるとしていた因果分析ツールですが、統計的因果推論について調べてみることにしました。
LiNGAM
LiNGAMは、Linear Non-Gaussian Acyclic Modelの略称です。観測されたデータに対して、何の事前知識もなしに因果構造を発見する方法で、近年では因果探索(Causal Discovery)と呼ばれているようです。[1]
前提条件
データの事前知識は必要ありませんが、いくつかの仮定を満たす必要があります。
- 観測変数が因果順に並んでいること
- =リストの後方の変数が、前方の変数の原因にはならない
- =再帰構造にならない
- =因果グラフは、Directed Acyclic Graphs(DAG)になる
- ある変数
は、それより前方の変数
の線形関数で表される
は、撹乱、誤差、あるいはノイズ
は、任意定数
は、I番目の変数の因果順序の位置
- 撹乱
- ゼロ分散ではない非ガウス分布に従う連続値乱数
- 互いに独立:
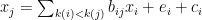
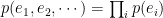
これらの仮定は、観測されていな交絡因子(cofounders)が無いこと(因果的十分性)を暗黙に仮定しています。
方程式
2番目の線形関数であるという仮定は、次のようなベクトル行列形式で書くことができます。
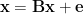
そして、この方程式は連立線形方程式になっているので、次のように解くことができます。

これは、「解法アルゴリズムの選び方」で説明した通り、解を線型結合(線形関数)に無理やり置き換えたことで、因果関係を連立線形方程式問題に置き換えたと見ることができます。
ここで、行列Bは、因果順の仮定により、対角成分ゼロの下三角行列になります。そのため、行列I–Bは、対角成分1の下三角行列にになります。これは、LU分解の行列Lと同じ形です。そして、この形の行列の場合、ガウスの消去法で必ず解を求めることができます。逆行列Aも、うまく順序を入れ替えると、対角成分がある下三角行列になります。
解法
さて、問題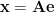
ただし、ICAは因果関係にとって不都合な点が2つあります。それは次のような点です。
- ICAでは独立成分の順序は任意だが、因果関係では因果順に並んでいなければならない(仮定1)
- ICAでは行列Aを適切にスケーリングするが、因果関係では対角成分が1に固定されていなければならない
そのため、因果関係を推定するには、ICAを計算する→規格化する→因果順に置換する、という手順が必要です。
アルゴリズム
以上により、仮定1〜3の下では、次のような因果発見アルゴリズムを構築できます。
LiNGAMアルゴリズム
- データ行列X(m×n)を、ICAによりX=ASと分解し、W=A^{-1}とする。(m:成分数、n:サンプル数、m<<n、S:撹乱行列(m×n)、A:混合行列(m×m))
- Wの成分を並べ替え、非ゼロ対角成分を持つW’を作成する。(ゼロ割防止)
- W’の各行をその行の対角成分で割り、対角成分を1にする。(規格化)
- B’=I–W’を計算する。
- B=PB’P^Tが下三角行列となるような置換行列Pを見つけるため、
を最小化する。(因果順)
ステップ5の最適化問題の目的関数f(P)は、下三角行列Bの対角成分および上三角成分はゼロにならないといけないことに由来します。各成分を二乗することで正負成分の打ち消しを防ぎ、二乗和f(P)=0の時の置換行列Pを探索する最適化問題にしています。(参考記事)
アルゴリズムのより詳細な説明は、参考文献1をご覧ください。
DirectLiNGAM
現在では、上記のICAを使ったLiNGAMではなく、DirectLiNGAMの方がデフォルトになっているようです。
ICAを使ったLiNGAMには、2つの問題点がありました。[2]
- ICAアルゴリズムで行われる最適化が、パラメータの設定のよっては収束しない。または、収束するパラメータを見つけることが難しい。
- 置換アルゴリズムがスケール不変ではなく、スケールによっておかしな因果順が推定されてしまう。しかし、本来、因果順はスケールに依存しないはずである。
これらを解決するために、DirectLiNGAMではICAを使わずに因果探索を行います。
アプローチ
DirectLiNGAMの計算アプローチは、下図のように、補題1・補題2・系1の3つの矢印をたどることで計算されます。
LiNGAMでは入力データ
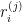

DirectLiNGAMのアプローチでは、ICAは、入力データから残差への変換に置き換えられます。
理論
補題1は、次のようなものです。
補題1
インプットデータ
Shimizu, S., et. al (2011)が、厳密にLiNGAM条件(3つの前提とデータの有限性)を満たすとする。
について回帰された残差を
と書くことにする。このとき、
と独立であれば、
外生変数とは、因果の連鎖の出発点になる変数のことで、出力の矢印しかない変数のことです。言い換えると、入力データの中には説明変数となるデータが存在しない変数のことで、入力されたどのデータにも従属しない変数(=独立変数)となります。
補題1は、あるデータ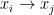
この非独立性が成立するには、撹乱
Darmois-Skitovitchの定理
ランダムな独立変数
Shimizu, S., et. al (2011)の線型結合によって、2つのランダムな変数
を、
と定義する。このとき、
が独立ならば、
となる全ての変数
はガウス分布となる。
この定理は、逆に解釈すると、変数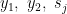
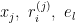
証明方針は、外生変数は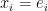
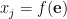
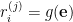
詳しい証明は、参考文献2をご覧ください。
補題2とその系1は、次のようなものです。
補題2
インプットデータ
Shimizu, S., et. al (2011)で回帰された(p-1)個の
と書くことにする。このとき、残差ベクトル
を満たす。ここで、
は行と列の同時並べ替えで厳密に下三角になるように並べ替えられる行列で、
の要素は非ガウス分布かつ互いに独立である。
系1
インプットデータ
Shimizu, S., et. al (2011)と書き、外生変数
となる。
直観的には、データxがLiNGAM型の方程式x=Bx+eを満たす場合、データの線型結合である回帰残差rもr=Br+eを満たすことは想像できると思います。
ですが、補題2と系1の証明はいまいち理解できませんでした。もし、理解できる方がいたら教えていただけると助かります。
アルゴリズム
これらを踏まえると、次のようなアルゴリズムを組むことができます。
DirectLiNGAMアルゴリズム
- 初期化
- p次元乱数ベクトル
- 添字集合
- p×n次元乱数行列
- 空のカーネル添字集合
- 外生変数の固定添字
- p次元乱数ベクトル
- For j=1…p-1:
- Kに含まれずUに含まれるの添字iについて、
- 同様に、データ行列
から残差行列
を作成する。
- 残差ベクトル
を探索する。
- 独立データの添字mを、Kに追加する。
、
- Kに含まれずUに含まれるの添字iについて、
- 残ったデータの添字をKに追加する。(Kは添字が因果順序に並んでいる)
- Kの順序で下三角行列Bを構成し、元のデータ


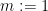
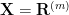
まとめ
LiNGAMとは、Linear Non-Gaussian Acyclic Modelの略称で、次の3つの前提を持つ因果探索アルゴリズムです。
- 因果グラフの非循環性(DAG性)
- 因果の線形性
- 撹乱(誤差)の非ガウス性
上記の条件を持つとき、独立成分分析(ICA)と行列Bを下三角行列へ置換することで、因果グラフを推定できます。
また、DirectLiNGAMとは、最小二乗法による回帰の残差空間に問題を置き換えて、ICAを使わずにLiNGAMと同じ因果を導出する方法です。
LiNGAMの弱点は、3つの前提にあります。この前提から、次の2つの限界があることが分かります。
- 例えば、入手したデータに循環がないことを予め知ることはできないかもしれません。その場合、LiNGAMによって得られた因果が正しいことは保証できません。
- 原因と結果が線形の関係にはならないかもしれません。例えば、ある一定値までは増加し、それを超えると減少に転じる逆U字型の関係は、線形では表せません。
このような限界はあるものの、事前知識なしでデータだけを使って因果探索を行う方法は少ないので、まずは使ってみると良いのではないでしょうか。
参考文献
- Shimizu, S., Hoyer, P. O., Hyvärinen, A., Kerminen, A., & Jordan, M. (2006). A linear non-Gaussian acyclic model for causal discovery. Journal of Machine Learning Research, 7(10).
- Shimizu, S., Inazumi, T., Sogawa, Y., Hyvärinen, A., Kawahara, Y., Washio, T., … & Bollen, K. (2011). DirectLiNGAM: A direct method for learning a linear non-Gaussian structural equation model. The Journal of Machine Learning Research, 12, 1225-1248.


