
公開データを統計分析してみようとしていて、変数の尺度の違いによって使うべき相関係数が違うことを思い出しました。
順序変数用のポリコリック相関のpython実装例はこちらの記事にありましたが、動作保証はできないそうなので自分で作ってみることにしました。
まあ、プログラムを作成し終わった頃にsemopy.polycorrというパッケージがあることに気づいて、作る意味は無くなったんですが記録として残しておこうと思います。
目次
変数の尺度
統計学では、データ変数をその尺度の性質に応じて4つに分類しています。
- 質的変数(カテゴリー変数、離散変数)
- 名義尺度・・・順序に意味はなく、区分・分類を表す数値(例:性別、郵便番号)
- 順序尺度・・・順序に意味はあるが、間隔には意味がないもの(例:順位、好き嫌い)
- 量的変数(連続変数)
- 間隔尺度・・・目盛りが等間隔になっているもの(例:気温)
- 比例尺度・・・原点があり、間隔や比率に意味があるもの(例:長さ、速度)
心理学的なアンケート調査では、リッカート式の尺度(5件法の例:「1.全くそう思わない」「2.そう思わない」「3.どちらとも言えない」「4.そう思う」「5.とてもそう思う」といった尺度)がよく用いられますが、これを間隔尺度として良いかどうかは、統計学でかなり検討されています。現在の統計学の結論としては、
- リッカート式5件法以下→順序尺度→ピアソン相関は使用不可
- リッカート式6件法以上→間隔尺度→ピアソン相関が使用可
となっていて、間隔尺度であればピアソン相関が使えます。ピアソン相関は、最もよく使われる相関係数の計算方法で、Excelでも計算できてお手軽です。
逆に、順序尺度になってしまうとピアソン相関が使えない(計算できても正しさを保証できない)ため、特殊な計算方法が必要になり、相関係数の計算ですら手間がかかってしまいます。
そのため、何かと使い勝手の良い間隔尺度にするために、研究レベルでは6件法や7件法がよく使われています。
ポリコリック相関
順序尺度かつ回答に正規分布が想定される場合(=5件法以下のリッカート式尺度の場合)には、ポリコリック相関で相関係数を計算することができます。
ポリコリック相関は、
- 2つの回答データのクロス集計表(回答頻度分布表)を作る
- 相関係数ρをパラメータとして、2次元正規分布をクロス集計表に最適化する
- 最適化した2次元正規分布のパラメータρを相関係数とする
といった手順で計算されます。頻度分布を計算するため、データは離散値である必要があります。
2次元正規分布は、次のような公式で計算できます。

これを、図示すると次のようになります。

図1.2次元正規分布の相関係数による違い
図1を見ると、パラメータρが1に近づくほど、斜め45°方向に直線的な分布になることが分かります。回答分布が45°方向の直線に近づくほど、2つのデータの相関が強いことになります。
従って、得られた回答データによくフィットする相関係数ρを見つけ出すことが、ポリコリック相関の問題設定になります。
近似計算の実装
Olsson(1979)は、2つ実装方法を示しています。1つは、確率分布である2次元正規分布をメッシュに切る境界値をパラメータとして、相関係数と同時に最適化させる厳密な方法です。もう1つは、境界値は固定して、各セルの確率分布を周辺分布から近似的に計算してしまう方法です。まずは、簡単な後者で実装することにします。
クロス集計表の作成
測定された2つの順序変数データから、下記のようなクロス集計表(出現頻度表)を作成します。

図2、クロス集計表と変数の対応関係
ここでは、s,rはそれぞれデータx,yの種類数になります。例えば、データxが1~10の選択肢から選ぶ質問項目だった場合、s=10となります。
これを、pythonコードにすると次のようになります。
def frequency_table(x,y):
"""
Create a frequency table by cross-tabulatin of x by y.
Parameters
----------
x : pd.DataFrame
An array of categorial data
y : pd.DataFrame
An array of categorial data
Returns
-------
n : np.ndarray
A frequency matrix
"""
r = max(x) - min(x) + 1
s = max(y) - min(y) + 1
n = np.zeros((r,s))
i0 = min(x)
j0 = min(y)
for i, j in zip(x,y):
n[ i-i0, j-j0 ] += 1
#print(n)
return n
境界値の作成
次に、2次元正規分布をメッシュに分割するために、データxから境界値ベクトルを作成します。例えば、選択肢4の境界値は、
- 選択肢4以下が選ばれる確率P4を、選択肢4以下の回答頻度(n1+n2+n3+n4)/Nとする
- 1次元累積正規分布関数の逆関数Φ1-1(P4)から、その確率になる座標a4をメッシュの境界値とする
といった手順で考えます。順序変数なので、最大選択肢以下が選ばれる確率は必ず1となり、必ずas=∞となります。また、境界値ベクトルには、下限値としてa0=-∞を加えます。これを、s=7の場合に図示すると次のようになります。

図3、回答分布と正規分布と境界値の対応関係
数学的には、次のようになります。
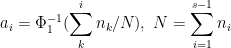
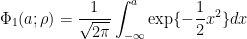
プログラムコードでは、numpy.unique関数を使って頻度データに変換して、scipy.norm.ppf関数で正規分布の座標値を計算しています。
# 正規分布の境界値を生成する
def estimate_boundaries( x, inf=10 ):
"""
Compute boundary thresholds by inversion CDF.
Parameters
----------
x : pd.DataFrame
An array of categorial data
inf : int, optional
inifinity value on normal distribution. Default value is 10.
Returns
-------
a : np.ndarray
An array of boundary thresholds.
cat : np.ndarray
An array of category numbers.
"""
cat, cnt = np.unique(x,return_counts=True)
n = cnt.sum()
a = norm.ppf( cnt.cumsum() / n )[:-1]
a = np.append( -inf, np.append( a, inf ) )
#print(a)
return a, cat
確率分布の作成
2つの境界値ベクトルa,bで表現されるメッシュのセル毎の確率を、2次元累積正規分布関数Φ2を使って計算します。

累積正規分布関数は、指定されたメッシュ座標(a,b)以下の長方形領域の確率を計算しているので、下図のセル(赤枠部分)は4点(ai-1,bj-1), (ai,bj-1), (ai-1,bj), (ai,bj)の累積分布から計算できます。

図4、メッシュ座標と累積分布関数によるセル確率の算出イメージ
セル部分の確率を求めるには、4点の累積分布関数から次のようにして求められます。
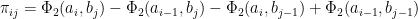
上式の右辺第4項は、第2項と第3項で引きすぎた分を補完するための項です。この計算を図示すると、次のような面積の計算になります。

図5、セル確率の算出公式のイメージ
プログラムコードは次のようになります。
def probability_table(a,b,rho,means=[0,0],var=[1,1]):
"""
Compute the probabilities than observations fall into cells.
Parameters
----------
a : np.ndarray
An array of cell boundary thresholds of data x
b : np.ndarray
An array of cell boundary thresholds of data y
rho : float
A correlation value as off-diagonal elements of 2x2 covariant matrix
means : list, float, optional
2 mean values, default values are [0,0] (standardized).
var : list, float, optional
Diagonal elements of 2x2 covariant matrix, default values are [1,1].
Returns
-------
pi : np.ndarray
A matrix of probabilities in cell.
"""
cov = np.array([[var[0],rho],[rho,var[1]]])
m = len(a) - 1
n = len(b) - 1
pi = np.zeros((m,n))
#phi2 = multivariate_normal(cov=cov)
for i in range(m):
for j in range(n):
#a1b1 = phi2d.cdf(mesh2d[i+1,j+1])
#a1b0 = phi2d.cdf(mesh2d[i+1,j ])
#a0b1 = phi2d.cdf(mesh2d[i ,j+1])
#a0b0 = phi2d.cdf(mesh2d[i ,j ])
#pi2d[i-1,j-1] = a1b1 - a1b0 - a0b1 + a0b0
pi[i,j] = mvn.mvnun([a[i],b[j]],[a[i+1],b[j+1]],means,cov)[0]
return pi
2次元累積正規分布関数は、scipy.stats.multivariate_normal.cdf()関数を使用すれば計算できます。しかし、scipy.statsには、マニュアルに記載されていないmvnがあるそうで、この中のmvn.mvnun()関数を使うと上記の赤枠部分を1回で計算することができるようです。そして、こちらを使った方が計算時間が短いです。下記のコードでは、cdf関数を使うバージョンはコメントアウトしています。また、配列piへの格納はインデックスを-1ずつずらしています。
尤度最適化による相関係数の計算
2次元正規分布のセル(i,j)が選ばれる確率をπijとすると、そのセルがnij回選択される確率はπijnijとなります。同様に、ある回答分布{nij | i=1,2,…,s, j=1,2,…r}が得られる確率は、相関係数ρをパラメータとして、全セルの確率の積で計算することができます。
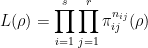
この関数は、尤もらしさの度合いを表すので、尤度関数と呼ばれています。
ところで、測定された回答分布は最も確率が高い分布であったと考えられます。言い換えると、測定された回答分布に対して、尤度が最大になっているはずです。そのため、尤度Lを最大化する最適化問題を解くことで、最適な相関係数ρを見つけることができます。
積算だらけの尤度関数は、コンピュータを使った数値計算では、桁数がオーバーフローしてしまいがちです。桁数がオーバーフローすると、有効桁数が無くなってしまい、計算結果がランダムになってしまいます。そこで、尤度関数の代わりに、対数尤度関数がよく用いられます。
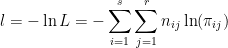
負号は、最大化問題を最小化問題にするために付けています。これは、scipy.optimizeの最小化アルゴリズムを使うためです。
実際のプログラムコードでは、対数尤度関数を局所関数fun_likelihood()として実装し、scipy.optimizeのminimize_scalar()関数の第一引数(目的関数)に渡しています。minimize_scalar()関数は、第一引数(最適化変数)が単一の値(スカラー値)の場合に使用できます。また、相関係数は必ず-1≦ρ≦1となるので境界条件を設定しています。
# 単一の相関値を計算する
def corr_single(x,y):
"""
Compute a poychoric correlation value between categorical data x and y.
Parameters
----------
x : np.ndarray
An array of categorical data x
y : np.ndarray
An array of categorical data y
Returns
-------
rho : float
A correlation value.
"""
a, a_cat = estimate_boundaries(x)
b, b_cat = estimate_boundaries(y)
n = frequency_table(x,y)
def fun_likelihood(rho):
pi = probability_table(a,b,rho)
return -( n * np.log(pi) ).sum()
res = minimize_scalar( fun_likelihood,bounds=(-1,1),args=(),method="bounded")
if res.success :
return res.x
#return res.x[0]
else:
print(res)
raise(ValueError("Optimization is falure."))
相関行列の作成
上記までのプログラムcorr_singleは、2本のデータ間の相関係数を計算するもので、semopy.polychoric_corr()にも実装されています。しかし、pandas.DataFrame.cor()関数などのように、複数データ間の相関行列を計算してくれると便利です。そこで、pandas.DataFrame形式でデータセットを受け取り、相関行列を返す関数を作っておきます。
# 相関行列を計算する
def corr(data):
"""
Compute a poychoric correlation matrix of categorical data.
Parameters
----------
data : pd.DataFrame
An array of ordered data x
Returns
-------
corr : np.ndarray
A correlation matrix.
"""
n = len(data.columns)
corr = np.eye(n)
for i in range(0,n):
x = data.iloc[:,i]
for j in range(i+1,n):
y = data.iloc[:,j]
rho = corr_single(x,y)
corr[i,j] = corr[j,i] = rho
return corr
厳密計算の実装
上記の近似計算では、境界値を定数として扱いましたが、本来は境界値も最適化変数として扱う必要があります。すなわち、相関係数ρと境界値a, bを1本のベクトル変数(ρ, a, b)とした1+s+r次元の最適化を行う必要があります。多次元最適化の多くは、目的関数の微分を用いています。そのため、目的関数である対数尤度関数の微分の計算式を解析的に算出しておく必要があります。
対数尤度関数の最適化変数(相関係数と境界値)による微分は以下のように計算でき、確率分布πijの微分計算の問題に帰着します。
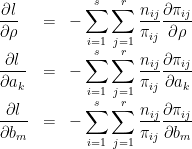
そして、確率分布πijは4つの2次元累積正規分布関数Φ2で構成されていたので、結局のところ2次元累積正規分布関数Φ2の微分を算出することになります。
境界値による微分の計算
境界値a,bによる2次元累積正規分布関数の微分は、計算の結果、次のようになります。
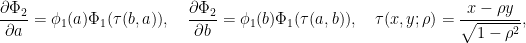
これの証明は、補足Aをご覧ください。これを使うと、確率分布πijの微分は次のように計算されます。
![\begin{array}{lcl}\displaystyle\frac{\partial \pi_{ij}}{\partial a_k}&=&\displaystyle\frac{\partial \Phi_2(a_{i},b_{j})}{\partial a_k}-\frac{\partial \Phi_2(a_{i-1},b_{j})}{\partial a_k}-\frac{\partial \Phi_2(a_{i},b_{j-1})}{\partial a_k}+\frac{\partial \Phi_2(a_{i-1},b_{j-1})}{\partial a_k}\\ &=&\displaystyle\left[ \frac{\partial \Phi_2(a_{k},b_{j})}{\partial a_k}-\frac{\partial \Phi_2(a_{k},b_{j-1})}{\partial a_k}\right]\left[\delta_{i,k} - \delta_{i-1,k}\right]\\ &=&\displaystyle\phi_1(a_k)\bigg[\Phi_1\left(\tau(b_j,a_k)\right)-\Phi_1\left(\tau(b_{j-1},a_k)\right)\bigg] \left[\delta_{i,k}-\delta_{i-1,k}\right]\end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Blcl%7D%5Cdisplaystyle%5Cfrac%7B%5Cpartial+%5Cpi_%7Bij%7D%7D%7B%5Cpartial+a_k%7D%26%3D%26%5Cdisplaystyle%5Cfrac%7B%5Cpartial+%5CPhi_2%28a_%7Bi%7D%2Cb_%7Bj%7D%29%7D%7B%5Cpartial+a_k%7D-%5Cfrac%7B%5Cpartial+%5CPhi_2%28a_%7Bi-1%7D%2Cb_%7Bj%7D%29%7D%7B%5Cpartial+a_k%7D-%5Cfrac%7B%5Cpartial+%5CPhi_2%28a_%7Bi%7D%2Cb_%7Bj-1%7D%29%7D%7B%5Cpartial+a_k%7D%2B%5Cfrac%7B%5Cpartial+%5CPhi_2%28a_%7Bi-1%7D%2Cb_%7Bj-1%7D%29%7D%7B%5Cpartial+a_k%7D%5C%5C+%26%3D%26%5Cdisplaystyle%5Cleft%5B+%5Cfrac%7B%5Cpartial+%5CPhi_2%28a_%7Bk%7D%2Cb_%7Bj%7D%29%7D%7B%5Cpartial+a_k%7D-%5Cfrac%7B%5Cpartial+%5CPhi_2%28a_%7Bk%7D%2Cb_%7Bj-1%7D%29%7D%7B%5Cpartial+a_k%7D%5Cright%5D%5Cleft%5B%5Cdelta_%7Bi%2Ck%7D+-+%5Cdelta_%7Bi-1%2Ck%7D%5Cright%5D%5C%5C+%26%3D%26%5Cdisplaystyle%5Cphi_1%28a_k%29%5Cbigg%5B%5CPhi_1%5Cleft%28%5Ctau%28b_j%2Ca_k%29%5Cright%29-%5CPhi_1%5Cleft%28%5Ctau%28b_%7Bj-1%7D%2Ca_k%29%5Cright%29%5Cbigg%5D+%5Cleft%5B%5Cdelta_%7Bi%2Ck%7D-%5Cdelta_%7Bi-1%2Ck%7D%5Cright%5D%5Cend%7Barray%7D&bg=ffffff&fg=000&s=0&c=20201002)
ここで、δkjはクロネッカーのデルタです。以上により、対数尤度関数の境界値による微分は次のようになります。
![\begin{array}{lcl} \displaystyle\frac{\partial l}{\partial a_k}&=&\displaystyle -\sum_{i=1}^s\sum_{j=1}^r\frac{n_{ij}}{\pi_{ij}}\phi_1(a_k)\bigg[\Phi_1\left(\tau(b_j,a_k)\right)-\Phi_1\left(\tau(b_{j-1},a_k)\right)\bigg]\left[\delta_{i,k}-\delta_{i-1,k}\right]\\ &=&\displaystyle -\sum_{j=1}^r\left[\frac{n_{kj}}{\pi_{kj}}-\frac{n_{k+1,j}}{\pi_{k+1,j}}\right]\phi_1(a_k)\bigg[\Phi_1\left(\tau(b_j,a_k)\right)-\Phi_1\left(\tau(b_{j-1},a_k)\right)\bigg]\end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Blcl%7D+%5Cdisplaystyle%5Cfrac%7B%5Cpartial+l%7D%7B%5Cpartial+a_k%7D%26%3D%26%5Cdisplaystyle+-%5Csum_%7Bi%3D1%7D%5Es%5Csum_%7Bj%3D1%7D%5Er%5Cfrac%7Bn_%7Bij%7D%7D%7B%5Cpi_%7Bij%7D%7D%5Cphi_1%28a_k%29%5Cbigg%5B%5CPhi_1%5Cleft%28%5Ctau%28b_j%2Ca_k%29%5Cright%29-%5CPhi_1%5Cleft%28%5Ctau%28b_%7Bj-1%7D%2Ca_k%29%5Cright%29%5Cbigg%5D%5Cleft%5B%5Cdelta_%7Bi%2Ck%7D-%5Cdelta_%7Bi-1%2Ck%7D%5Cright%5D%5C%5C+%26%3D%26%5Cdisplaystyle+-%5Csum_%7Bj%3D1%7D%5Er%5Cleft%5B%5Cfrac%7Bn_%7Bkj%7D%7D%7B%5Cpi_%7Bkj%7D%7D-%5Cfrac%7Bn_%7Bk%2B1%2Cj%7D%7D%7B%5Cpi_%7Bk%2B1%2Cj%7D%7D%5Cright%5D%5Cphi_1%28a_k%29%5Cbigg%5B%5CPhi_1%5Cleft%28%5Ctau%28b_j%2Ca_k%29%5Cright%29-%5CPhi_1%5Cleft%28%5Ctau%28b_%7Bj-1%7D%2Ca_k%29%5Cright%29%5Cbigg%5D%5Cend%7Barray%7D&bg=ffffff&fg=000&s=0&c=20201002)
この計算のプログラムコードは、次のようになりました。1次元正規確率密度関数φ1にはscipy.stats.norm.pdf()関数を用い、1次元累積正規分布関数Φ1にはscipy.stats.norm.cdf()関数を用いています。
# 尤度関数の微分
def der_likelihood(a,b,rho,n,pi,dpi,loc=0,scale=1):
"""
Compute derivatives of likelihood function.
Parameters
----------
a : np.ndarray
An array of cell boundary thresholds of data x
b : np.ndarray
An array of cell boundary thresholds of data y
rho : float
A correlation value as off-diagonal elements of 2x2 covariant matrix
n : np.ndarray
Two dimensional frequency table.
pi : np.ndarray
Two dimensional probability table.
dpi : np.ndarray
Two dimensional probability derivatives table.
loc : float, optional
A center value of cumulative distribution function (CDF) [default=0]
scale : float, optional
A coefficient value of cumulative distribution function (CDF) [default=1]
Returns
-------
dfdr : float
A derivative for likelihood function by rho.
dfda : np.ndarray
Derivatives for likelihood function by a.
dfdb : np.ndarray
Derivatives for likelihood function by b.
"""
s = len(a)
r = len(b)
sigma = np.sqrt(1-rho*rho)
npi = n / pi # size=(s-1,r-1)
npidpi = npi * dpi
# dfdr
dfdr = -( npi * dpi ).sum()
# dfda
dfda = np.zeros((s))
phi_a = norm.pdf(a)
for k in range(1,s-1):
for j in range(1,r):
cdf00 = norm.cdf( (b[j ]-rho*a[k])/sigma )
cdf10 = norm.cdf( (b[j-1]-rho*a[k])/sigma )
dfda[k] -= ( npi[k-1,j-1] - npi[k,j-1] ) * phi_a[k] * ( cdf00 - cdf10 )
# dfdb
dfdb = np.zeros((r))
phi_b = norm.pdf(b)
for m in range(1,r-1):
for i in range(1,s):
cdf00 = norm.cdf( (a[i ]-rho*b[m])/sigma )
cdf10 = norm.cdf( (a[i-1]-rho*b[m])/sigma )
dfdb[m] -= ( npi[i-1,m-1] - npi[i-1,m] ) * phi_b[m] * ( cdf00 - cdf10 )
return dfdr,dfda,dfdb
相関係数による微分の計算
相関係数ρによる2次元累積正規分布関数の微分は、結果的に非常にシンプルで、次のようになります。
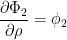
ただし、この証明はやや難解なので付録Bにゆずります。
これより、確率分布πijの相関係数微分は、次のような計算式になります。

これは、確率分布πijと同時に計算できるため、プログラムコードは次のようにしました。変数dpiが微分値になります。
def probability_table(a,b,rho,means=[0,0],var=[1,1],eps=1e-15,deriv=False):
"""
Compute the probabilities than observations fall into cells.
Parameters
----------
a : np.ndarray
An array of cell boundary thresholds of data x
b : np.ndarray
An array of cell boundary thresholds of data y
rho : float
A correlation value as off-diagonal elements of 2x2 covariant matrix
means : list, float, optional
2 mean values, default values are [0,0] (standardized).
var : list, float, optional
Diagonal elements of 2x2 covariant matrix, default values are [1,1].
Returns
-------
pi : np.ndarray
A matrix of probabilities in cell.
"""
cov = np.array([[var[0],rho],[rho,var[1]]])
m = len(a) - 1
n = len(b) - 1
pi = np.zeros((m,n))
phi2 = multivariate_normal(cov=cov)
if deriv :
dpi = np.zeros((m,n))
for i in range(m):
for j in range(n):
#a1b1 = phi2.cdf( [a[i+1],b[j+1]] )
#a1b0 = phi2.cdf( [a[i+1],b[j ]] )
#a0b1 = phi2.cdf( [a[i ],b[j+1]] )
#a0b0 = phi2.cdf( [a[i ],b[j ]] )
#pival = a1b1 - a1b0 - a0b1 + a0b0
pival = mvn.mvnun([a[i],b[j]],[a[i+1],b[j+1]],means,cov)[0]
pi[i,j] = max( pival, eps )
da1b1 = phi2.pdf( [a[i+1],b[j+1]] )
da1b0 = phi2.pdf( [a[i+1],b[j ]] )
da0b1 = phi2.pdf( [a[i ],b[j+1]] )
da0b0 = phi2.pdf( [a[i ],b[j ]] )
dpi[i,j] = da1b1 - da1b0 - da0b1 + da0b0
return pi,dpi
else:
for i in range(m):
for j in range(n):
#a1b1 = phi2.cdf( [a[i+1],b[j+1]] )
#a1b0 = phi2.cdf( [a[i+1],b[j ]] )
#a0b1 = phi2.cdf( [a[i ],b[j+1]] )
#a0b0 = phi2.cdf( [a[i ],b[j ]] )
#pival = a1b1 - a1b0 - a0b1 + a0b0
pival = mvn.mvnun([a[i],b[j]],[a[i+1],b[j+1]],means,cov)[0]
pi[i,j] = max( pival, eps )
return pi
対数尤度関数の相関係数微分は、確率分布πijの相関係数微分を使用し、次の公式に基づいて計算します。
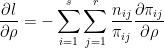
プログラムコードは、すでに前述の対数尤度関数の境界値微分のプログラムコードの中で示してありますが、再掲しておきます。
# 尤度関数の微分
def der_likelihood(a,b,rho,n,pi,dpi,loc=0,scale=1):
"""
Compute derivatives of likelihood function.
Parameters
----------
a : np.ndarray
An array of cell boundary thresholds of data x
b : np.ndarray
An array of cell boundary thresholds of data y
rho : float
A correlation value as off-diagonal elements of 2x2 covariant matrix
n : np.ndarray
Two dimensional frequency table.
pi : np.ndarray
Two dimensional probability table.
dpi : np.ndarray
Two dimensional probability derivatives table.
loc : float, optional
A center value of cumulative distribution function (CDF) [default=0]
scale : float, optional
A coefficient value of cumulative distribution function (CDF) [default=1]
Returns
-------
dfdr : float
A derivative for likelihood function by rho.
dfda : np.ndarray
Derivatives for likelihood function by a.
dfdb : np.ndarray
Derivatives for likelihood function by b.
"""
s = len(a)
r = len(b)
sigma = np.sqrt(1-rho*rho)
# dfdr
npi = n / pi # size=(s-1,r-1)
dfdr = -( npi * dpi ).sum()
# dfda
dfda = np.zeros((s))
phi_a = norm.pdf(a)
for k in range(1,s-1):
for j in range(1,r):
cdf00 = norm.cdf( (b[j ]-rho*a[k])/sigma )
cdf10 = norm.cdf( (b[j-1]-rho*a[k])/sigma )
dfda[k] -= ( npi[k-1,j-1] - npi[k,j-1] ) * phi_a[k] * ( cdf00 - cdf10 )
# dfdb
dfdb = np.zeros((r))
phi_b = norm.pdf(b)
for m in range(1,r-1):
for i in range(1,s):
cdf00 = norm.cdf( (a[i ]-rho*b[m])/sigma )
cdf10 = norm.cdf( (a[i-1]-rho*b[m])/sigma )
dfdb[m] -= ( npi[i-1,m-1] - npi[i-1,m] ) * phi_b[m] * ( cdf00 - cdf10 )
return dfdr,dfda,dfdb
多次元最適化
上記の微分計算式を使って、対数尤度関数が最小値になるように相関係数と境界値を最適化します。
最適化には、scipy.opitimize.minimum()関数を使用します。目的関数の一階微分を必要とするアルゴリズムが多いので、局所関数に目的関数とその導関数を定義し、コールバック関数としてminimum関数に渡しています。
# 単一の相関値を計算する
def corr_single(x,y,method=None,grad=None,options=None,inf=10,maxval=0.9999,verbose=False):
"""
Compute a poychoric correlation value between categorical data x and y.
Parameters
----------
x : np.ndarray
An array of categorical data x
y : np.ndarray
An array of categorical data y
method : str or None, optional
Type of solver for scipy.optimize.minimize.
Type should be one of
* 'Nelder-Mead'
* 'Powell'
* 'CG'
* 'BFGS'
* 'Newton-CG'
* 'L-BFGS-B'
* 'TNC'
* 'COBYLA'
* 'SLSQP'
* 'trust-constr'
* 'dogleg'
* 'trust-ncg'
* 'trust-exact'
* 'trust-krylov'
* None - call approimated algorithm
see also, SciPy optimize API reference.
grad : str of None, optional
Type of gradient calculation method for the solvers using gradients.
* 'numeric' - use numerical gradients g={f(x+dx)-f(x)}/dx
* None - use exact derivatives of likelihood function.
Default is None
options: dict, optional
Options for solvers including solver specific options.
inf : int, optional
inifinity value on normal distribution. Default value is 10.
maxval: float, optional
upper/lower bound values of a correlation rho.
Default is 0.9999.
verbose: bool, optional
If True, print more optimization messages.
Returns
-------
rho : float
A correlation value.
"""
# vecter packager
def pack(_rho,_a,_b):
_s = len(_a)
_r = len(_b)
_z = np.zeros((1+_s-2+_r-2))
_z[0] = _rho
_z[1:_s-1] = _a[1:_s-1]
_z[_s-1:_s+_r-3] = _b[1:_r-1]
return _z
# vecter unpackager
def unpack(_z,_s,_r):
if len(_z) != _s+_r-3:
raise(ValueError("Invalid Size : len(_z) == _s + _r - 3"))
_rho = _z[0]
_a = _z[1:_s-1]
_b = _z[_s-1:_s+_r-3]
_a = np.append( -inf, np.append( _a, inf ) )
_b = np.append( -inf, np.append( _b, inf ) )
return _rho,_a,_b
def make_bounds(_s,_r):
_n = _s-2 + _r-2
lb = np.zeros((1+_n))
ub = np.zeros((1+_n))
kp = np.empty((1+_n),dtype=bool)
lb[0] = -1.0
lb[1:_n+1] = -inf
ub[0] = 1.0
ub[1:_n+1] = inf
kp[0] = True
kp[1:_n+1] = False
bounds = Bounds(lb,ub,keep_feasible=kp)
return bounds
a, a_cat = estimate_boundaries(x,inf=inf)
b, b_cat = estimate_boundaries(y,inf=inf)
n = frequency_table(x,y)
if method is None :
def fun_likelihood(rho):
pi = probability_table(a,b,rho)
f = -( n * np.log(pi) ).sum()
#print("rho=",rho," f=",f)
return f
res = minimize_scalar( fun_likelihood,bounds=(-1,1),args=(),method="bounded")
if res.success :
return res.x
else:
print(res)
raise(ValueError("Optimization is falure."))
elif method == "deriv_check":
check_deriv(a,b,n)
raise(ValueError("Only do derivertive checker."))
else:
s = len(a)
r = len(b)
z_init = pack( 0.0, a, b )
def f_mlikelihood(z):
#print("z=\n",z)
#print("a*dz=\n",z-z_init)
rho,aa,bb = unpack(z,s,r)
rho = max(min(rho,maxval),-maxval)
pi = probability_table(aa,bb,rho)
f = -( n * np.log(pi) ).sum()
#print("rho=",rho," f=",f)
return f
def df_mlikelihood(z):
#print("z=\n",z)
rho,aa,bb = unpack(z,s,r)
rho = max(min(rho,maxval),-maxval)
pi,dpi = probability_table(aa,bb,rho,deriv=True)
dfdr,dfda,dfdb = der_likelihood(aa,bb,rho,n,pi,dpi)
df = pack(dfdr,dfda,dfdb)
#print("dfdr=\n",dfdr)
#print("dfda=\n",dfda)
#print("dfdb=\n",dfdb)
return df
func = f_mlikelihood
if method == "CG" or \
method == "BFGS" or \
method == "Newton-CG" or \
method == "L-BFGS-B" or \
method == "TNC" or \
method == "SLSQP" or \
method == "dogleg" or \
method == "trust-ncg" or \
method == "trust-krylov" or \
method == "trust-exact" or \
method == "trust-constr" :
if grad is None:
jacobian = df_mlikelihood
elif grad == "numeric":
jacobian = "2-piont"
else:
jacobian = None
if method == "Nelder-Mead" or \
method == "L-BFGS-B" or \
method == "TNC" or \
method == "SLSQP" or \
method == "Powell" or \
method == "trust-constr" or \
method == "COBYLA":
bounds = make_bounds(s,r)
else:
bounds = None
if options is None:
if verbose :
opts = {'disp':True,'return_all':True}
else:
opts = {}# {'disp':True,'return_all':True}
if method == "Powell" or \
method == "SLSQP" :
opts["ftol"] = 1e-8
if method == "Newton-CG" :
opts["xtol"] = 1e-8
if method == "BFGS" or \
method == "CG" or \
method == "L-BFGS-B":
opts["gtol"] = 1e-6
else:
opts = options
res = minimize( func, z_init, jac=jacobian, method=method, bounds=bounds, options=opts)
if res.success :
#print(res)
return res.x[0]
else:
print(res)
raise(ValueError("Optimization is falure."))
ローカル関数のpack, unpackは、最適化変数を1本のベクトルにまとめたり(pack )、バラバラにしたり(unpack)する関数です。
使い方
実行方法は、付録Cのpolychoric.pyと同じディレクトリで、次のようなスクリプトを実行します。
import pandas as pd
import polychoric
d = pd.read_csv("surveydata.csv",index_col=0) #データ読み込み
cor = polychoric.corr(d,method="SLSQP")
print(cor) # 分析結果表示
テスト結果
正規分布の乱数生成で作成した3つのデータに対して実行した結果は、次の通りです。ほぼ同じ数値に収束していることが分かります。
semopy:
[[ 1. -0.00118679 -0.00122767]
[-0.00118679 1. -0.01342726]
[-0.00122767 -0.01342726 1. ]]
scalar:
[[ 1. -0.00118679 -0.00122767]
[-0.00118679 1. -0.01342726]
[-0.00122767 -0.01342726 1. ]]
SLSQP:
[[ 1. -0.00118757 -0.00122929]
[-0.00118757 1. -0.01343353]
[-0.00122929 -0.01343353 1. ]]
Powell:
[[ 1. -0.00119692 -0.00121755]
[-0.00119692 1. -0.01342726]
[-0.00121755 -0.01342726 1. ]]
L-BFGS-B:
[[ 1. -0.00118747 -0.00122899]
[-0.00118747 1. -0.01341609]
[-0.00122899 -0.01341609 1. ]]
CG:
Desired error not necessarily achieved due to precision loss.
Nelder-Mead:
[[ 1. -0.00120309 -0.00120568]
[-0.00120309 1. -0.0134277 ]
[-0.00120568 -0.0134277 1. ]]
COBYLA:
[[ 1. -0.00117314 -0.00120528]
[-0.00117314 1. -0.01339612]
[-0.00120528 -0.01339612 1. ]]
BFGS:
Desired error not necessarily achieved due to precision loss.
“semopy”は、semopy.polycorrモジュールを使用した結果です。”scalar”は、微分なしの近似計算で計算した結果です。その他のラベルは、最適化計算手法の名前です。CG法とBFGS法は、最適化に失敗してしまいましたが、今のところ改善策は分かりません。
付録
A. 2次元累積正規分布関数の境界値微分の証明
指数関数の指数部を平方完成する。

ただし、

また、xからτへの変数変換で、次のように係数がつく点には注意が必要である。
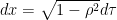
分布関数のyの二乗部分について指数関数を括り出した部分は、1次元正規分布密度関数に等しくなる。また、平方完成した部分をτ2に変数変換することで、残りの部分はτについての1次元累積正規分布関数に等しくなる。2次元累積正規分布関数は、x,yについて対称性があるため、xとy、およびaとbについて入れ替えても同様の計算が行える。
これにより、xまたはyについての一階積分の公式になり、2次元累積分布関数のxまたはyによる微分は、被積分関数だけが残る。
![\displaystyle\frac{\partial \Phi_2}{\partial a}=\frac{\partial }{\partial x}\int_{-\infty}^adx\phi_1(x)\Phi_1(\tau(b,x))\Bigg|_{x=a}=\left[\phi_1(x)\Phi_1(\tau(b,x))\right]^a_{-\infty}=\phi_1(a)\Phi_1(\tau(b,a)),](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%5Cfrac%7B%5Cpartial+%5CPhi_2%7D%7B%5Cpartial+a%7D%3D%5Cfrac%7B%5Cpartial+%7D%7B%5Cpartial+x%7D%5Cint_%7B-%5Cinfty%7D%5Eadx%5Cphi_1%28x%29%5CPhi_1%28%5Ctau%28b%2Cx%29%29%5CBigg%7C_%7Bx%3Da%7D%3D%5Cleft%5B%5Cphi_1%28x%29%5CPhi_1%28%5Ctau%28b%2Cx%29%29%5Cright%5D%5Ea_%7B-%5Cinfty%7D%3D%5Cphi_1%28a%29%5CPhi_1%28%5Ctau%28b%2Ca%29%29%2C&bg=ffffff&fg=000&s=0&c=20201002)
B. 2次元累積正規分布関数の相関係数微分の証明
2次元累正規分布関数に対して、変数C,Sを以下のように設定する。
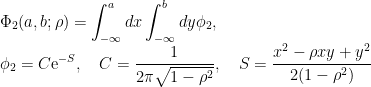
この時、変数Sについて、次のような関係が成立する。
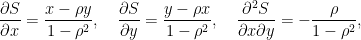

ここで、2次元正規分布密度関数φ2の相関係数微分は次のように計算される。
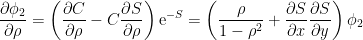
一方、xy二階微分は次のようになる。
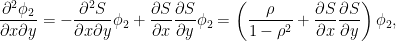
すなわち、以下が成立する。
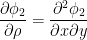
したがって、2次元累積正規分布関数の相関係数微分は、次のように計算される。
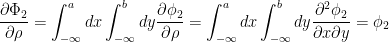
C. ソースコード polychoric.py
from scipy.stats import norm, mvn
from scipy.stats import multivariate_normal
from scipy.optimize import minimize, minimize_scalar
from scipy.optimize import Bounds, BFGS
import numpy as np
import semopy.polycorr as so
# カテゴリー変数を出現回数行列に変換する
def frequency_table(x,y):
"""
Create a frequency table by cross-tabulatin of x by y.
Parameters
----------
x : pd.DataFrame
An array of categorial data
y : pd.DataFrame
An array of categorial data
Returns
-------
n : np.ndarray
A frequency matrix
"""
r = max(x) - min(x) + 1
s = max(y) - min(y) + 1
n = np.zeros((r,s))
i0 = min(x)
j0 = min(y)
for i, j in zip(x,y):
n[ i-i0, j-j0 ] += 1
#print(n)
return n
# 正規分布の境界値を生成する
def estimate_boundaries( x, inf=10 ):
"""
Compute boundary thresholds by inversion CDF.
Parameters
----------
x : pd.DataFrame
An array of categorial data
inf : int, optional
inifinity value on normal distribution. Default value is 10.
Returns
-------
a : np.ndarray
An array of boundary thresholds.
cat : np.ndarray
An array of category numbers.
"""
cat, cnt = np.unique(x,return_counts=True)
n = cnt.sum()
a = norm.ppf( cnt.cumsum() / n )[:-1]
a = np.append( -inf, np.append( a, inf ) )
#print(a)
return a, cat
# 2次元ガウス分布(二変量正規分布)から組み合わせが得られる確率を計算する
def probability_table(a,b,rho,means=[0,0],var=[1,1],eps=1e-15,deriv=False):
"""
Compute the probabilities than observations fall into cells.
Parameters
----------
a : np.ndarray
An array of cell boundary thresholds of data x
b : np.ndarray
An array of cell boundary thresholds of data y
rho : float
A correlation value as off-diagonal elements of 2x2 covariant matrix
means : list, float, optional
2 mean values, default values are [0,0] (standardized).
var : list, float, optional
Diagonal elements of 2x2 covariant matrix, default values are [1,1].
Returns
-------
pi : np.ndarray
A matrix of probabilities in cell.
"""
cov = np.array([[var[0],rho],[rho,var[1]]])
m = len(a) - 1
n = len(b) - 1
pi = np.zeros((m,n))
phi2 = multivariate_normal(cov=cov)
if deriv :
dpi = np.zeros((m,n))
for i in range(m):
for j in range(n):
#a1b1 = phi2.cdf( [a[i+1],b[j+1]] )
#a1b0 = phi2.cdf( [a[i+1],b[j ]] )
#a0b1 = phi2.cdf( [a[i ],b[j+1]] )
#a0b0 = phi2.cdf( [a[i ],b[j ]] )
#pival = a1b1 - a1b0 - a0b1 + a0b0
pival = mvn.mvnun([a[i],b[j]],[a[i+1],b[j+1]],means,cov)[0]
pi[i,j] = max( pival, eps )
da1b1 = phi2.pdf( [a[i+1],b[j+1]] )
da1b0 = phi2.pdf( [a[i+1],b[j ]] )
da0b1 = phi2.pdf( [a[i ],b[j+1]] )
da0b0 = phi2.pdf( [a[i ],b[j ]] )
dpi[i,j] = da1b1 - da1b0 - da0b1 + da0b0
return pi,dpi
else:
for i in range(m):
for j in range(n):
#a1b1 = phi2.cdf( [a[i+1],b[j+1]] )
#a1b0 = phi2.cdf( [a[i+1],b[j ]] )
#a0b1 = phi2.cdf( [a[i ],b[j+1]] )
#a0b0 = phi2.cdf( [a[i ],b[j ]] )
#pival = a1b1 - a1b0 - a0b1 + a0b0
pival = mvn.mvnun([a[i],b[j]],[a[i+1],b[j+1]],means,cov)[0]
pi[i,j] = max( pival, eps )
return pi
def check_deriv(a,b,n):
def calc_f(rho):
pi = probability_table(a,b,rho)
f = -( n * np.log(pi) ).sum()
return f
def calc_fg(rho):
pi,dpi = probability_table(a,b,rho,deriv=True)
f = -( n * np.log(pi) ).sum()
dfdr= -( n *dpi / pi ).sum()
return f,dfdr
ub=1.0
lb=-1.0
maxpoints=50
print("DERIV CHECK")
for i in range(maxpoints):
rho = lb + (i+1)/maxpoints *(ub-lb)
f0,g0 = calc_fg(rho)
delta = 1e-1
while delta > 1e-14:
f1 = calc_f(rho+delta)
g1 = (f1-f0)/delta
if abs(g1-g0) < 1e-4 * abs(g0):
break
delta *= 0.1
print(i," rho=",rho," delta=",delta," g_exact=",g0," g_numer=",g1," delta_g=",abs(g1-g0)/abs(1e-14+g0))
# 尤度関数の微分
def der_likelihood(a,b,rho,n,pi,dpi,loc=0,scale=1):
"""
Compute derivatives of likelihood function.
Parameters
----------
a : np.ndarray
An array of cell boundary thresholds of data x
b : np.ndarray
An array of cell boundary thresholds of data y
rho : float
A correlation value as off-diagonal elements of 2x2 covariant matrix
n : np.ndarray
Two dimensional frequency table.
pi : np.ndarray
Two dimensional probability table.
dpi : np.ndarray
Two dimensional probability derivatives table.
loc : float, optional
A center value of cumulative distribution function (CDF) [default=0]
scale : float, optional
A coefficient value of cumulative distribution function (CDF) [default=1]
Returns
-------
dfdr : float
A derivative for likelihood function by rho.
dfda : np.ndarray
Derivatives for likelihood function by a.
dfdb : np.ndarray
Derivatives for likelihood function by b.
"""
s = len(a)
r = len(b)
sigma = np.sqrt(1-rho*rho)
npi = n / pi # size=(s-1,r-1)
npidpi = npi * dpi
# dfdr
dfdr = -( npi * dpi ).sum()
# dfda
dfda = np.zeros((s))
phi_a = norm.pdf(a)
for k in range(1,s-1):
for j in range(1,r):
cdf00 = norm.cdf( (b[j ]-rho*a[k])/sigma )
cdf10 = norm.cdf( (b[j-1]-rho*a[k])/sigma )
dfda[k] -= ( npi[k-1,j-1] - npi[k,j-1] ) * phi_a[k] * ( cdf00 - cdf10 )
# dfdb
dfdb = np.zeros((r))
phi_b = norm.pdf(b)
for m in range(1,r-1):
for i in range(1,s):
cdf00 = norm.cdf( (a[i ]-rho*b[m])/sigma )
cdf10 = norm.cdf( (a[i-1]-rho*b[m])/sigma )
dfdb[m] -= ( npi[i-1,m-1] - npi[i-1,m] ) * phi_b[m] * ( cdf00 - cdf10 )
return dfdr,dfda,dfdb
# 単一の相関値を計算する
def corr_single(x,y,method=None,grad=None,options=None,inf=10,maxval=0.9999,verbose=False):
"""
Compute a poychoric correlation value between categorical data x and y.
Parameters
----------
x : np.ndarray
An array of categorical data x
y : np.ndarray
An array of categorical data y
method : str or None, optional
Type of solver for scipy.optimize.minimize.
Type should be one of
* 'Nelder-Mead'
* 'Powell'
* 'CG'
* 'BFGS'
* 'Newton-CG'
* 'L-BFGS-B'
* 'TNC'
* 'COBYLA'
* 'SLSQP'
* 'trust-constr'
* 'dogleg'
* 'trust-ncg'
* 'trust-exact'
* 'trust-krylov'
* None - call approimated algorithm
see also, SciPy optimize API reference.
grad : str of None, optional
Type of gradient calculation method for the solvers using gradients.
* 'numeric' - use numerical gradients g={f(x+dx)-f(x)}/dx
* None - use exact derivatives of likelihood function.
Default is None
options: dict, optional
Options for solvers including solver specific options.
inf : int, optional
inifinity value on normal distribution. Default value is 10.
maxval: float, optional
upper/lower bound values of a correlation rho.
Default is 0.9999.
verbose: bool, optional
If True, print more optimization messages.
Returns
-------
rho : float
A correlation value.
"""
# vecter packager
def pack(_rho,_a,_b):
_s = len(_a)
_r = len(_b)
_z = np.zeros((1+_s-2+_r-2))
_z[0] = _rho
_z[1:_s-1] = _a[1:_s-1]
_z[_s-1:_s+_r-3] = _b[1:_r-1]
return _z
# vecter unpackager
def unpack(_z,_s,_r):
if len(_z) != _s+_r-3:
raise(ValueError("Invalid Size : len(_z) == _s + _r - 3"))
_rho = _z[0]
_a = _z[1:_s-1]
_b = _z[_s-1:_s+_r-3]
_a = np.append( -inf, np.append( _a, inf ) )
_b = np.append( -inf, np.append( _b, inf ) )
return _rho,_a,_b
def make_bounds(_s,_r):
_n = _s-2 + _r-2
lb = np.zeros((1+_n))
ub = np.zeros((1+_n))
kp = np.empty((1+_n),dtype=bool)
lb[0] = -1.0
lb[1:_n+1] = -inf
ub[0] = 1.0
ub[1:_n+1] = inf
kp[0] = True
kp[1:_n+1] = False
bounds = Bounds(lb,ub,keep_feasible=kp)
return bounds
a, a_cat = estimate_boundaries(x,inf=inf)
b, b_cat = estimate_boundaries(y,inf=inf)
n = frequency_table(x,y)
if method is None :
def fun_likelihood(rho):
pi = probability_table(a,b,rho)
f = -( n * np.log(pi) ).sum()
#print("rho=",rho," f=",f)
return f
res = minimize_scalar( fun_likelihood,bounds=(-1,1),args=(),method="bounded")
if res.success :
return res.x
else:
print(res)
raise(ValueError("Optimization is falure."))
elif method == "deriv_check":
check_deriv(a,b,n)
raise(ValueError("Only do derivertive checker."))
else:
s = len(a)
r = len(b)
z_init = pack( 0.0, a, b )
def f_mlikelihood(z):
#print("z=\n",z)
#print("a*dz=\n",z-z_init)
rho,aa,bb = unpack(z,s,r)
rho = max(min(rho,maxval),-maxval)
pi = probability_table(aa,bb,rho)
f = -( n * np.log(pi) ).sum()
#print("rho=",rho," f=",f)
return f
def df_mlikelihood(z):
#print("z=\n",z)
rho,aa,bb = unpack(z,s,r)
rho = max(min(rho,maxval),-maxval)
pi,dpi = probability_table(aa,bb,rho,deriv=True)
dfdr,dfda,dfdb = der_likelihood(aa,bb,rho,n,pi,dpi)
df = pack(dfdr,dfda,dfdb)
#print("dfdr=\n",dfdr)
#print("dfda=\n",dfda)
#print("dfdb=\n",dfdb)
return df
func = f_mlikelihood
if method == "CG" or \
method == "BFGS" or \
method == "Newton-CG" or \
method == "L-BFGS-B" or \
method == "TNC" or \
method == "SLSQP" or \
method == "dogleg" or \
method == "trust-ncg" or \
method == "trust-krylov" or \
method == "trust-exact" or \
method == "trust-constr" :
if grad is None:
jacobian = df_mlikelihood
elif grad == "numeric":
jacobian = "2-piont"
else:
jacobian = None
if method == "Nelder-Mead" or \
method == "L-BFGS-B" or \
method == "TNC" or \
method == "SLSQP" or \
method == "Powell" or \
method == "trust-constr" or \
method == "COBYLA":
bounds = make_bounds(s,r)
else:
bounds = None
if options is None:
if verbose :
opts = {'disp':True,'return_all':True}
else:
opts = {}# {'disp':True,'return_all':True}
if method == "Powell" or \
method == "SLSQP" :
opts["ftol"] = 1e-8
if method == "Newton-CG" :
opts["xtol"] = 1e-8
if method == "BFGS" or \
method == "CG" or \
method == "L-BFGS-B":
opts["gtol"] = 1e-6
else:
opts = options
res = minimize( func, z_init, jac=jacobian, method=method, bounds=bounds, options=opts)
if res.success :
#print(res)
return res.x[0]
else:
print(res)
raise(ValueError("Optimization is falure."))
# Converged pattern
#res = minimize( f_mlikelihood,z_init,jac="2-point",method="SLSQP",bounds=bounds,
# options={'ftol':1e-8,'eps':1e-6,'disp':True})
#res = minimize( f_mlikelihood,z_init,method="Powell",
# options={'ftol':1e-8,'xtol':1e-12,'disp':True,'return_all':True})
#res = minimize( f_mlikelihood,z_init,jac="2-point",method="BFGS",
# options={'gtol':1e-6,'xrtol':1e-8,'disp':True,'return_all':True} )
#res = minimize( f_mlikelihood,z_init,jac=df_mlikelihood,method="SLSQP",bounds=bounds,
# options={'ftol':1e-8,'disp':True})
#res = minimize( f_mlikelihood,z_init,jac=df_mlikelihood,method="L-BFGS-B",bounds=bounds,
# options={'gtol':1e-6,'disp':True})
#res = minimize( f_mlikelihood,z_init,jac=df_mlikelihood,method="L-BFGS-B",
# options={'gtol':1e-6,'disp':True})
# Not converged pattern
#res = minimize( f_mlikelihood,z_init,jac=df_mlikelihood,method="BFGS",
# options={'gtol':1e-6,'xrtol':1e-4,'disp':True,'return_all':True})
# 相関行列を計算する
def corr(data,method=None,grad=None,options=None,inf=10,maxval=0.9999,verbose=False):
"""
Compute a poychoric correlation matrix of categorical data.
Parameters
----------
data : pd.DataFrame
An array of categorical data x
method : str or None, optional
Type of solver for scipy.optimize.minimize.
Type should be one of
* 'Nelder-Mead'
* 'Powell'
* 'CG'
* 'BFGS'
* 'Newton-CG'
* 'L-BFGS-B'
* 'TNC'
* 'COBYLA'
* 'SLSQP'
* 'trust-constr'
* 'dogleg'
* 'trust-ncg'
* 'trust-exact'
* 'trust-krylov'
* 'semopy' - use semopy's polychoric_corr() function
* None - use an approimated algorithm
see also, SciPy optimize API reference.
grad : str of None, optional
Type of gradient calculation method for the solvers using gradients.
* 'numeric' - use numerical gradients g={f(x+dx)-f(x)}/dx
* None - use exact derivatives of likelihood function.
Default is None
options: dict, optional
Options for solvers including solver specific options.
inf : int, optional
inifinity value on normal distribution. Default value is 10.
maxval: float, optional
upper/lower bound values of a correlation rho.
Default is 0.9999.
verbose: bool, optional
If True, print more optimization messages.
Returns
-------
corr : np.ndarray
A correlation matrix.
"""
n = len(data.columns)
corr = np.eye(n)
if method == "semopy" :
for i in range(0,n):
x = data.iloc[:,i]
for j in range(i+1,n):
y = data.iloc[:,j]
rho = so.polychoric_corr(x,y)
corr[i,j] = corr[j,i] = rho
else:
for i in range(0,n):
x = data.iloc[:,i]
for j in range(i+1,n):
y = data.iloc[:,j]
rho = corr_single(x,y,method=method,grad=grad,options=options,
inf=inf,maxval=maxval,verbose=verbose)
corr[i,j] = corr[j,i] = rho
return corr
参考文献
- Olsson, U. (1979). Maximum likelihood estimation of the polychoric correlation coefficient. Psychometrika, 44(4), 443-460.
- 小杉考司「順序尺度の相関係数(ポリコリック相関係数)について」
- Qiita「様々な尺度の変数同士の関係を算出する(Python)」
https://qiita.com/shngt/items/45da2d30acf9e84924b7 - semopy.polycorr


