
こんにちは。やまもとです。
今回は、noteで書いていた記事「行列積計算を高速化してみた」があまりにも長いので、実際に高速化した経験をもとにポイントをまとめてみたいと思います。このときは、インテル製CPUを搭載したMacBook Proで、理論上の最高FLOPSの95~97%ほどの速度が出ました。
今回は、高速化の考え方のポイントをお話しします。
行列積って?
初めに、高校数学の線形代数で習っていると思いますが、行列積とは何かをおさらいしておきましょう。
簡単に言ってしまうと、行列積とは行列


高校だと3x3行列くらいしか扱わないので地道に計算すれば答えが出ますが、科学シミュレーションや機械学習では1000×1000行列といったサイズの行列が使われるため、とても手では計算していられません。そのため、コンピュータに計算してもらうのが当たり前になっています。

コンピュータで計算させるには?
コンピュータで行列積を計算するには、いちいち行列積コードを書く必要はありません。標準的なオープンライブラリBLASの中のDGEMMサブルーチンを、プログラムから呼び出すだけで計算することができます。
なお、DGEMMは、単なる行列積ではなく、一定の汎用性を持たせるように、次のような公式を計算しています。
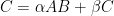
ここで、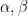
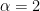
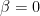

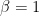
BLASはFORTRAN言語のライブラリなので、次のようにコードをプログラムに埋め込んで使用します。
CALL DGEMM(TRANSA,TRANSB,M,N,K,ALPHA,A,LDA,B,LDB,BETA,C,LDC)
ここで、A, B, Cは上記の行列を表し、ALPHAやBETAは上記の
BLASには、C言語のラッパーライブラリCBLASが用意されていて、C言語からも使用することができます。その関数宣言は次のようになっています。
void cblas_dgemm(const enum CBLAS_ORDER Order, const enum CBLAS_TRANSPOSE TransA,
const enum CBLAS_TRANSPOSE TransB, const int M, const int N,
const int K, const double alpha, const double *A,
const int lda, const double *B, const int ldb,
const double beta, double *C, const int ldc);
パラメータであるOrder, TransA, TransBは、enum型で次のように宣言されています。
enum CBLAS_ORDER {CblasRowMajor=101, CblasColMajor=102};
enum CBLAS_TRANSPOSE {CblasNoTrans=111, CblasTrans=112, CblasConjTrans=113};
TransAとTransBは前述の説明通り転置を指定するパラメータですが、OrderというのはCBLAS特有のパラメータになっています。
これは、FORTRAN言語の配列要素が、メモリ上で既定で列方向に連続アクセスになるように配置されているのに対し、C言語では直線的に配列要素が配置されているため、列方向に連続で並んでいるのか行方向に連続で並んでいるのか判断できないため、プログラマー自らが指定する必要があるので追加されています。CblasRowMajorを選ぶと行方向に連続を表し、CblasColMajorを選ぶと列方向に連続(FORTRANと同じ)を意味しています。

標準DGEMMの問題点
以前書いたこちらのnote記事でも性能比較をしていますが、はっきり言って、標準BLASのDGEMMは計算速度が遅いです。
そのため、CPUやGPUベンダー各社は、CPUやGPUに最適化したBLASライブラリを提供しています。Intel社ならMKL、nVIDIA社ならCuBLAS、オープンソースならOpenBLASあたりが有名です。実際、同じCPUを使っても、これら高速なライブラリだと標準BLASのおよそ10倍は高速です。
「10倍なら大した差ではない」と思われるかもしれませんが、「5分かかっていた計算が30秒しかかからない」と言えば、その差がわかるでしょうか?
あるいは、CPUの使用時間による従量課金性でサーバーを借りていた場合、費用支払い額が1/10になると言えば、イメージしやすいかもしれません。
ベンダー各社のBLASライブラリも、標準DGEMMと同じインターフェースで実装されているので、プログラムにリンクするライブラリファイルを差し替えるだけで、プログラムの処理速度が上がることがあります。

なぜ、標準DGEMMは遅いのか?
行列積をアルゴリズムにすると、そのプログラムには次のような特徴があります。
- 計算量
(三重ループ計算)
- メモリ使用量
(行列3個)
ここで、
一方、コンピュータが何らかの処理を行う場合、必要なデータはメインメモリ(主記憶装置)やキャッシュメモリに保持して置く必要があります。しかも、このメインメモリやキャッシュメモリは、コンピュータに搭載できる容量に限界があります。例えば、あなたのパソコンだと、メインメモリなら8GBとか、キャッシュメモリなら4MBといった容量までは搭載されているかもしれません。
行列1つのメモリ容量が8MB、キャッシュメモリの容量が4MBだとすると、行列1つをキャッシュメモリに保持することはできません。この場合、キャッシュメモリに保持されていたデータは、メインメモリに一時的に退避されます。
この一時退避の時間が、標準DGEMMの処理時間を遅くしてしまうのです。

また、現代のCPUには、計算効率を上げるために、SSE2やAVX2といったSIMD(Single Instruction and Multiple Data)命令という、複数のデータを一度に計算する命令が装備されています。しかし、この命令が使われるかどうかは、コンパイラがソースコードをうまく解釈し、SIMD命令に置き換えてくれるかどうかかかっています。
そのため、コンパイラがSIMD命令に置き換えてくれない場合、標準DGEMMの処理時間は遅くなります。
最後に、現代のCPUの処理時間とデータを各種メモリに読み書きする時間には、大きなギャップがあります。イメージでは、CPUの処理時間が0.1秒だったとしても、データを読み込む時間が10~100秒ほどかかります。当然、データがメモリ上に存在しなければCPUは計算できないので、データが読み込まれる間は何もしない待ち時間になります。
このCPUの待ち時間も、標準DGEMMの処理時間を遅くしている原因です。

DGEMMを高速化するには?
以上の理由から、行列積計算を高速化するには、大きく3つのポイントがあります。
- データの無駄な一時退避を徹底的に削減する
- 効率的なSIMD命令を可能な限り使用する
- CPUの待ち時間を徹底的に削減する
次回以降は、このポイントをどう実現するのかについて書こうと思います。
